Programming
django-imagekit
The need may arise for different versions of the same image to be used in different parts of your site. ImageKit is an app that takes care of...
What is Stashboard? For those of you that don’t know, Stashboard is an open source status page that runs on Google App Engine. It can be customized to display the status of any API or SaaS services. In this day and age, a page like this can be very beneficial …
Notice: This article is maintained for historical purposes. The Bixly Automate/Nebri OS platform that Bixly built, and this article features, is no longer available. Checkout Serverless Providers as an alternative.
For those of you that don’t know, Stashboard is an open source status page that runs on Google App Engine. It can be customized to display the status of any API or SaaS services. In this day and age, a page like this can be very beneficial for determining what pre-defined services (APIs or SaaS) are down and why or when they have experienced problems.
We can see that Stashboard has the potential to be very useful. So why should we worry about making a clone that works with Nebri? The first reason is to show how much faster this is with Nebri! Also, there are two downfalls to Stashboard in its current state. While it’s nice to be able to see if a service is down, if we want any actions to be taken due to certain status updates, we must manually check the statuses and take said actions. With Nebri, we can set up events that trigger whenever we receive a status that indicates one of our services is down, taking the manual checks out of the equation. We can also take this the other way and send notifications when a previously down service has been restarted and is running again.
The other downfall is the way statuses are updated; according to Stashboard‘s documentation and source code, statuses can only be updated by incoming requests. Meaning you have to make an API request to Stashboard to update any status. Since Stashboard is open source, we could clone it and add code to handle these issues. That being said, the code needed to expand Stashboard currently would be much more extensive vs creating a clone in Nebri.
OK! Let’s get started, shall we? If you would like to follow along with the code base that I wrote, check out the github repo! Let’s start by straight up cloning Stashboard‘s functionality into a Nebri instance, then we’ll talk about the improvements I mentioned earlier. So, let’s break down our problem and list what we need to make this a success.
Well, let’s start at the top of the list.
from nebriosmodels import NebriOSModel, NebriOSField, NebriOSReference
class Service(NebriOSModel):
name = NebriOSField(required=True)
description = NebriOSField()
date_added = NebriOSField(required=True)
def current_status(self):
try:
statuses = ServiceStatus.filter(service=self)
statuses.sort(key=lambda x: x.date_added)
return statuses[0].status
except:
return None
def get_last_4_days(self):
try:
to_return = []
today = datetime.now().replace(hour=23, minute=59, second=59)
check_date_end = today - timedelta(days=1)
check_date_start = check_date_end.replace(hour=0, minute=0, second=0)
for _ in range(4):
statuses = ServiceStatus.filter(service=self, date_added__gte=check_date_start, date_added__lte=check_date_end)
found_down = False
found_up = False
message = 'up'
if len(statuses) == 0:
to_return.append({
'date': check_date_start.date().isoformat(),
'message': 'no data'
})
else:
for s in statuses:
if s.running == True:
found_up = True
else:
found_down = True
if found_up and found_down:
message = 'warning'
if not found_up and found_down:
message = 'down'
to_return.append({
'date': check_date_start.date().isoformat(),
'message': message
})
check_date_end = check_date_start - timedelta(seconds=1)
check_date_start = check_date_start - timedelta(days=1)
return to_return
except Exception as e:
return str(e)
def get_json(self):
return {'name': self.name,
'description': self.description,
# make sure to make your dates JSON serializable
'date_added': self.date_added.isoformat(),
'current_status': self.current_status()}
class ServiceStatus(NebriOSModel):
service = NebriOSReference(Service, required=True)
status_string = NebriOSField(required=True, default='up')
running = NebriOSField(required=True, default=False)
description = NebriOSField()
date_added = NebriOSField(required=True)
alerted = NebriOSField(required=True, default=False)
def get_json(self):
return {'status': self.status_string,
'description': self.description,
'running': self.running,
# make sure your dates are JSON serializable
'date_added': self.date_added.isoformat()}
Notice that ServiceStatus has both `status_string` and `running`. `status_string` can be set to anything that you like. Personally, I would set it to human readable statuses that make sense at a glance, but can include more information if needed. I also included a boolean `running`. I added this so there would be less ambiguity when it comes to testing if a service is actually up or not instead of making a guess depending on `status_string`. Now that we have models created, let’s look at the basic functionality that we’ll need for getting and setting attributes. The main thing to remember here is to make everything JSON serializable,which is why I added helper methods to the models. This will bite you in the butt otherwise. So, let’s take a look at the code for retrieving information.
from stashboardmodels import Service, ServiceStatus
def get_info(service=None, display=False):
if service is None:
# get info for all services
return_data = []
services = Service.filter()
for service in services:
data = {'service': service.get_json(), 'statuses': []}
if display:
data['statuses'] = service.get_last_4_days()
else:
statuses = ServiceStatus.filter(service=service)
for s in statuses:
data['statuses'].append(s.get_json())
return_data.append(data)
return return_data
else:
service = Service.get(name=service)
statuses = ServiceStatus.filter(service=service)
return_data = {'service': service.get_json(), 'statuses': []}
for s in statuses:
return_data['statuses'].append(s.get_json())
return return_data
This may look a little daunting at first, but I promise it’s not as crazy as it seems. When I wrote `get_info`, I assumed that it would be used for multiple request types. So, we can send a service name and get all info about that service, or not send a service name, and get info about all services. Now let’s take a look at setting up new services.
def create_service(data):
try:
try:
service = Service(
name=data['name'],
description=data.get('description', ''),
date_added=datetime.now()
)
except:
service = Service(
name=data.name,
description=data.description,
date_added=datetime.now()
)
service.save()
return 'Successfully Created'
except Exception as e:
return str(e)
This function may be a little confusing due to the nested try statements. The reason that I built this function in this manner is because this will be used by both external requests and requests made from Nebri cards. We try to extract data from the request in two different ways so we can handle if the data is in dictionary format or model format. This functionality is pretty similar to updating statuses.
def set_status(data):
try:
service = Service.get(name=data['service'])
try:
status = ServiceStatus(
service=service,
date_added=datetime.now(),
description=data.get('description', ''),
status=data['status']
)
except:
status = ServiceStatus(
service=service,
date_added=datetime.now(),
description=data.description,
status=data.status
)
status.save()
return 'Successfully Created'
except Exception as e:
return str(e)
Now we have our base utils set up and ready to go. Let’s look at API endpoints next. NOTE: if you aren’t using cards, many of these API endpoints are not needed. Instead of pasting them in one big chunk, let’s break them apart like our util file. First, let’s look at endpoints for getting info. For information on setting up authentication in your Nebri instance, see this github repo.
from stashboardutils import get_info
from nebrios_authentication import oauth_required
import json
@oauth_required(realm='stashboard')
def get_service_status_history(request):
try:
service = request.POST.service
except:
try:
service = json.loads(request.BODY)['service']
except:
try:
service = request.BODY['service']
except:
return HttpResponseBadRequest
return get_info(service=service)
def form_get_service_status_history(request):
try:
if request.is_authenticated:
return get_info(service=request.FORM.service)
else:
return HttpResponseForbidden
except:
return HttpResponseBadRequest
@oauth_required(realm='stashboard')
def get_services_statuses(request):
return get_info()
def form_get_services_statuses(request):
try:
if request.is_authenticated:
return get_info()
else:
return HttpResponseForbidden
except:
return HttpResponseBadRequest
So, now we have endpoints for getting info about a specific service or all services. Seems pretty basic, right? One thing to note in external requests is we check both `request.POST` and `request.BODY` for our appropriate data. The other thing is in our form endpoints (which will be used solely by Nebri cards), we check to ensure the request is authenticated. If the request originated in Nebri, it will be authenticated. Otherwise, it may be an external app trying to hit an endpoint that it shouldn’t.
from nebrios_authentication import oauth_required
from stashboardutils import create_service
import json
@oauth_required(realm='stashboard')
def new_service(request):
try:
name = request.POST.name
return create_service(request.POST)
except:
try:
name = request.BODY['name']
return create_service(request.BODY)
except:
try:
name = json.loads(request.BODY)['name']
return create_service(json.loads(request.BODY))
except:
return HttpResponseBadRequest
def form_new_service(request):
try:
if request.is_authenticated:
return create_service(request.FORM)
else:
return HttpResponseForbidden
except:
return HttpResponseBadRequest
Our endpoints for creating services look very similar to the endpoints for getting information, don’t they? Guess what? So do updating statuses.
from nebrios_authentication import oauth_required
from stashboardutils import set_status
import json
@oauth_required(realm='stashboard')
def update_status(request):
try:
service = request.POST.service
return set_status(request.POST)
except:
try:
service = request.BODY['service']
return set_status(request.BODY)
except:
try:
service = json.loads(request.BODY)['service']
return set_status(json.loads(request.BODY))
except:
return HttpResponseBadRequest
def form_update_status(request):
try:
if request.is_authenticated:
return set_status(request.FORM)
else:
return HttpResponseForbidden
except:
return HttpResponseBadRequest
You may be asking at this point, ok so why didn’t we put all the functionality in an api endpoint instead of a utils file? Reusability! In Nebri, it’s not considered kosher to import API functions in a rule script. So, we put functionality that will be used by both in a libraries util file.
So, now we have all of our base functionality that essentially clones Stashboard‘s current functionality. If you aren’t using cards, you can skip to the next section. 🙂 In my example app, I’ve created three cards to assist with displaying information, creating services, and updating statuses.
<polymer-element name="stashboard-stat-display" extends="nebrios-element">
<template>
<h2>StashBoard Clone Stats</h2>
<template repeat="false">
:
<template repeat="false">
<br> -
</template><br><br>
</template>
<paper-button on-click="">Refresh Statuses</paper-button>
<nebrios-ajax id="get_services_statuses" auto="true"
url="/api/v1/stashboard/form_get_last4_statuses"
on-response="">
</nebrios-ajax>
</template>
<script>
Polymer("stashboard-stat-display", {
onResponse: function(event, response) {
this.services = response.response;
console.log(this.services);
},
getAllServiceStatuses: function() {
this.$.get_services_statuses.go();rt
}
});
</script>
</polymer-element>
The above card script is relatively primitive in that it only lists services and their current status. This can be expanded to display all statuses, the most recent four statuses, or really anything you would like. If you scroll back up to `get_info`, you can see that the function returns all defined services with a list of all statuses. It’s up to you to decide how to display the information you get.
<polymer-element name="stashboard-new-service" extends="nebrios-form" target="stashboard.form_new_service">
<template>
<h2>New Stashboard Clone Service</h2>
<nebrios-string id="name" label="Service Name" required="true"></nebrios-string>
<nebrios-string id="description" label="Service Description"></nebrios-string>
</template>
<script>
Polymer("stashboard-new-service", {});
</script>
</polymer-element>
This is the most basic card in this example. Filling out the form and submitting will create a new service for you. From there, you are welcome to update the status of said service via this next card.
<polymer-element name="stashboard-update-status" extends="nebrios-form" target="stashboard.form_update_status">
<template>
<h2>Set Stashboard Clone Service Status</h2>
<nebrios-select id="service" label="Service" options=""></nebrios-select>
<nebrios-string id="status" label="Service Status" required="true"></nebrios-string>
<nebrios-string id="description" label="Service Status Description"></nebrios-string>
<nebrios-ajax id="load_options" auto="true"
url="/api/v1/stashboard/form_get_services_options"
on-response="">
</nebrios-ajax>
</template>
<script>
Polymer("stashboard-update-status", {
services: [],
onResponse: function(event, response) {
this.services = response.response;
this.$.service.setupOptions();
}
});
</script>
</polymer-element>
So that’s it! All you need to duplicate Stashboard‘s current functionality inside your Nebri instance. To compare code, see Stashboard’s github repo. In total, Stashboard uses 18,029 lines of Python code, while our version uses a measly 618 lines including utilized libraries. If we take out libraries and look at just functionality code, Stashboard clocks in at 1,656 loc, while we’re currently at 246. For all code line counts, I use CLOC. To set up and use the same script as I am, see the top answer in this stackoverflow question. Now, let’s take a look at our proposed improvements.

So, we have our basic functionality all done. All rule script code in this section can be found in the examples directory of this repo. Let’s say that any time a service goes down, we want to receive an email stating which service is down and the status. First, I added a field `alerted` to our ServiceStatus model. This will help with debouncing and will keep us from getting duplicate alerts.
class ServiceStatus(NebriOSModel):
service = NebriOSReference(Service, required=True)
status_string = NebriOSField(required=True, default='up')
running = NebriOSField(required=True, default=True)
description = NebriOSField()
date_added = NebriOSField(required=True)
alerted = NebriOSField(required=True, default=False)
def get_json(self):
return {'status': self.status_string,
'description': self.description,
'running': self.running,
# make sure your dates are JSON serializable
'date_added': self.date_added.isoformat()}
Now let’s create a rule script that listens to `running`. If `running` is False and `alerted` is False, we should alert the user that this service is down.
class stashboard_trigger_alerts(NebriOS):
listens_to = ['running']
def check(self):
return self.running is False and \
self.kind == 'servicestatus' and \
self.alerted is False
def action(self):
message = "%s service is down with status %s" % (self.service.name, self.status_string)
send_email("example@example.com", message)
It’s that simple. This script will run for each service status that is created. Notice I’m checking `self.kind == ‘servicestatus’`. This is a fail safe to only apply this code to the correct model. If there is ever another model created with a field called `running` and we didn’t include the kind check, those instances would also have this action taken on them. This example is pretty basic, but multiple rule scripts can be added for more complex behavior.
class stashboard_trigger_aws(NebriOS):
listens_to = ['running']
def check(self):
return self.running is False and \
self.kind == 'servicestatus' and \
self.alerted is False and \
self.service.name == 'Amazon AWS'
def action(self):
message = "%s service is down with status %s" % (self.service.name, self.status_string)
send_email("example@example.com", message)
This script will only trigger if the associated service name is Amazon AWS. Let’s look at one more example for when a service comes back online.
class stashboard_trigger_up(NebriOS):
listens_to = ['running']
def check(self):
return self.running == True and \
self.kind == 'servicestatus' and \
self.alerted == False
def action(self):
message = "%s service has come back online with status %s" % (self.service.name, self.status_string)
send_email("example@example.com", message)
That’s all there is to event handling. It’s as simple (or complex) as you want to make it! If you’re paying attention to lines of code, we’re at 653 including examples scripts at this point.
Here’s the fun part. While Stashboard only handles incoming status updates, we’re going to add a rule script that will check external APIs or SaaS to see if they are down or not. We’ll be using requests for this functionality. In order to install requests on your Nebri instance, you must ssh and pip install. I chose to ssh in and pip install through PyCharm. See Google App Engine documentation for more information on adding libraries to App Engine applications like Stashboard.
So, let’s add a function to the Service model to check if service name is a url. We’ll also add a new field `do_monitor`. This field is to trigger rule scripts to wake up.
class Service(NebriOSModel):
name = NebriOSField(required=True)
description = NebriOSField()
date_added = NebriOSField(required=True)
def current_status(self):
try:
statuses = ServiceStatus.filter(service=self)
statuses.sort(key=lambda x: x.date_added)
return statuses[0].status
except:
return None
def get_last_4_days(self):
try:
to_return = []
today = datetime.now().replace(hour=23, minute=59, second=59)
check_date_end = today - timedelta(days=1)
check_date_start = check_date_end.replace(hour=0, minute=0, second=0)
for _ in range(4):
statuses = ServiceStatus.filter(service=self, date_added__gte=check_date_start, date_added__lte=check_date_end)
found_down = False
found_up = False
message = 'up'
if len(statuses) == 0:
to_return.append({
'date': check_date_start.date().isoformat(),
'message': 'no data'
})
else:
for s in statuses:
if s.running == True:
found_up = True
else:
found_down = True
if found_up and found_down:
message = 'warning'
if not found_up and found_down:
message = 'down'
to_return.append({
'date': check_date_start.date().isoformat(),
'message': message
})
check_date_end = check_date_start - timedelta(seconds=1)
check_date_start = check_date_start - timedelta(days=1)
return to_return
except Exception as e:
return str(e)
def get_json(self):
return {'name': self.name,
'description': self.description,
# make sure to make your dates JSON serializable
'date_added': self.date_added.isoformat(),
'current_status': self.current_status()}
def is_url(self):
try:
requests.get(self.name)
return True
except:
return False
Now that we have the ability to determine whether or not our service is a url, let’s set up a rule script to check if the server is up.
import requests
class stashboard_check_site_status(NebriOS):
listens_to = ['do_monitor']
def check(self):
return self.do_monitor == True and \
self.is_url() == True
def action(self):
try:
response = requests.get(self.name, timeout=240, allow_redirects=True)
if 200 <= response.status_code < 300:
self.running = True
self.status_string = 'up'
else:
self.running = False
self.status_string = 'down'
except:
# either we reached our timeout, or the url isn't appropriate
self.running = False
self.status_string = 'down'
# for debouncing purposes
self.do_monitor = False
Notice we’re allowing redirects in these requests. If a service has moved and redirects, we need to follow to see if the actual service is available. Instead of handling it ourselves, let’s just let requests handle it. So, we’re looking for a status code in the 2xx range for a request to be successful and to indicate that the given service is available.
Alright, we have our rule script set up and listening to `do_monitor`. Now we need to set up a drip to actually set `do_monitor` so this thing will run. First, let’s set up another rule script that will be triggered by our drip.
from stashboardmodels import Service
class stashboard_setup_monitoring(NebriOS):
listens_to = ['stashboard_setup_monitoring']
def check(self):
return self.stashboard_setup_monitoring == True
def action(self):
all_services = Service.filter()
for service in all_services:
if service.is_url():
service.do_monitor = True
service.save()
# for debouncing purposes
self.stashboard_setup_monitoring = 'Ran'
Now let’s set up a drip to trigger this script. Drips can be created by clicking ‘Advanced’ in the left hand sidebar, then selecting ‘Drips’.
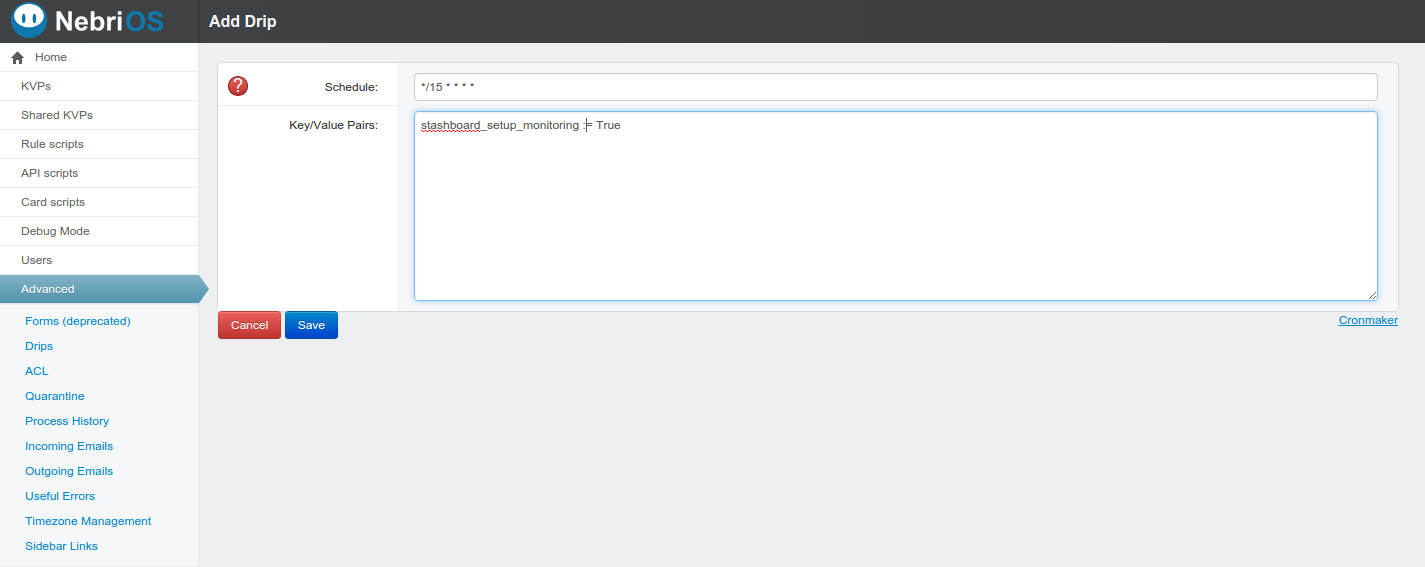
So, from our cron syntax, we can see that this drip will run every 15 minutes. The interval that this runs at is completely up to you. So, every time this drip is triggered, it sets our `stashboard_setup_monitoring` KVP, which triggers the rule script that updates `do_monitor` on all of our services that are urls. That’s it!
After all this, our Nebri instance not only keeps track of our service statuses, but it alerts us for any reason that we can think of to watch, and checks all services that are urls on a regular basis. All that in 684 lines of code. If you add requests’ code base in, we’re at 12,717 lines of code.
Now what? Well, if you are using cards, this is done. Your functionality is ready to go and use. If you want to use this from an external app, there are Nebri clients created by yours truly available for use.
Python: https://github.com/nebrie/python-nebri-authentication
jQuery: https://github.com/nebrie/jquery-nebri-authentication
NodeJS: https://github.com/nebrie/nodejs-nebri-authentication
AngularJS: https://github.com/nebrie/angular-nebri-authentication
The need may arise for different versions of the same image to be used in different parts of your site. ImageKit is an app that takes care of...
Reducing css and javascript page load size is integral to web development. Minimization will reduce web page size as well as the overhead cost of...
In the previous entry, “Bixly How-To: integrate django with facebook – part1”, we used the Facebook Javascript SDK to provide access to the Graph API...